
124
vues

Dernière mise à jour le

L'une des plus grosses erreurs des nouveaux propriétaires de sites Web n'est pas d'examiner leur fichier robots.txt. Alors qu'est-ce que c'est et pourquoi est-ce si important? Nous avons vos réponses.
Si vous possédez un site Web et que vous vous souciez de l'intégrité du référencement de votre site, vous devez vous familiariser avec le fichier robots.txt de votre domaine. Croyez-le ou non, il s'agit d'un nombre inquiétant de personnes qui lancent rapidement un domaine, installent un site Web WordPress rapide et ne prennent jamais la peine de faire quoi que ce soit avec leur fichier robots.txt.
C'est dangereux. Un fichier robots.txt mal configuré peut en fait détruire la santé SEO de votre site et compromettre toutes les chances que vous pourriez avoir pour augmenter votre trafic.
le Robots.txt Le fichier porte bien son nom, car il s'agit essentiellement d'un fichier qui répertorie les directives des robots Web (comme les robots des moteurs de recherche) sur la manière et les éléments à explorer sur votre site Web. Il s'agit d'une norme Web suivie par des sites Web depuis 1994 et tous les principaux robots d'indexation Web y adhèrent.
Le fichier est stocké au format texte (avec une extension .txt) dans le dossier racine de votre site Web. En fait, vous pouvez afficher le fichier robot.txt de n'importe quel site Web simplement en tapant le domaine suivi de /robots.txt. Si vous essayez ceci avec groovyPost, vous verrez un exemple de fichier robot.txt bien structuré.
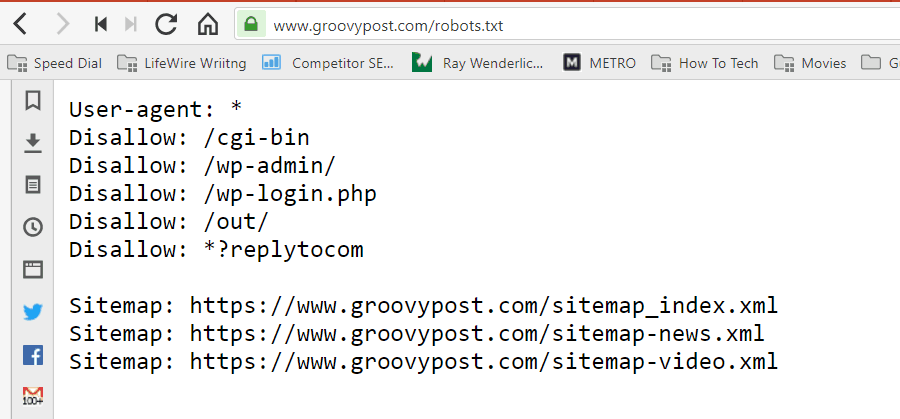
Le fichier est simple mais efficace. Cet exemple de fichier ne fait pas de différence entre les robots. Les commandes sont envoyées à tous les robots en utilisant le Agent utilisateur: * directif. Cela signifie que toutes les commandes qui le suivent s'appliquent à tous les robots qui visitent le site pour l'explorer.
Vous pouvez également spécifier des règles spécifiques pour des robots d'indexation spécifiques. Par exemple, vous pouvez autoriser Googlebot (le robot d'exploration de Google) à explorer tous les articles de votre site, mais vous pouvez souhaiter interdire au robot d'exploration de sites Web russe Yandex Bot d'explorer des articles sur votre site contenant des informations désobligeantes sur Russie.
Il existe des centaines de robots d'exploration de sites Web qui parcourent Internet pour trouver des informations sur les sites Web, mais les 10 plus courants dont vous devriez vous préoccuper sont répertoriés ici.
En prenant l'exemple de scénario ci-dessus, si vous vouliez autoriser Googlebot à tout indexer sur votre site, mais que vous vouliez empêcher Yandex d'indexer le contenu de votre article en russe, vous devez ajouter les lignes suivantes à votre robots.txt fichier.
User-agent: googlebot
Interdire: Interdire: / wp-admin /
Interdire: /wp-login.php
Agent utilisateur: yandexbot
Interdire: Interdire: / wp-admin /
Interdire: /wp-login.php
Interdire: / russie /
Comme vous pouvez le voir, la première section empêche uniquement Google d'explorer votre page de connexion WordPress et vos pages administratives. La deuxième section bloque Yandex du même, mais aussi de toute la zone de votre site où vous avez publié des articles avec du contenu anti-russe.
Ceci est un exemple simple de la façon dont vous pouvez utiliser le Refuser pour contrôler des robots d'exploration spécifiques qui visitent votre site Web.
La désactivation n'est pas la seule commande à laquelle vous avez accès dans votre fichier robots.txt. Vous pouvez également utiliser l'une des autres commandes qui indiqueront comment un robot peut explorer votre site.
Gardez à l'esprit que les bots seulement écoutez les commandes que vous avez fournies lorsque vous spécifiez le nom du bot.
Une erreur courante que les gens font est d'interdire des zones comme / wp-admin / de tous les bots, mais spécifiez ensuite une section googlebot et interdisez uniquement d'autres zones (comme / about /).
Étant donné que les robots ne suivent que les commandes que vous spécifiez dans leur section, vous devez reformuler toutes les autres commandes que vous avez spécifiées pour tous les robots (en utilisant * user-agent).
Gardez à l'esprit que le fichier robots.txt est conçu pour aider les robots légitimes (comme les robots des moteurs de recherche) à explorer votre site plus efficacement.
Il existe de nombreux robots malveillants qui explorent votre site pour faire des choses comme gratter des adresses e-mail ou voler votre contenu. Si vous voulez essayer d'utiliser votre fichier robots.txt pour empêcher ces robots d'exploration d'explorer quoi que ce soit sur votre site, ne vous embêtez pas. Les créateurs de ces robots d'exploration ignorent généralement tout ce que vous avez mis dans votre fichier robots.txt.
Faire en sorte que le moteur de recherche Google explore autant de contenu de qualité que possible sur votre site Web est une préoccupation majeure pour la plupart des propriétaires de sites Web.
Cependant, Google ne dépense qu'un nombre limité budget d'exploration et taux d'exploration sur des sites individuels. Le taux d'exploration est le nombre de demandes par seconde que Googlebot fera à votre site pendant l'événement d'exploration.
Plus important est le budget d'exploration, qui est le nombre total de demandes que Googlebot fera pour explorer votre site en une seule session. Google «dépense» son budget d'exploration en se concentrant sur les zones de votre site qui sont très populaires ou qui ont changé récemment.
Vous n'êtes pas aveugle à ces informations. Si vous visitez Outils Google pour les webmasters, vous pouvez voir comment le robot d'exploration gère votre site.
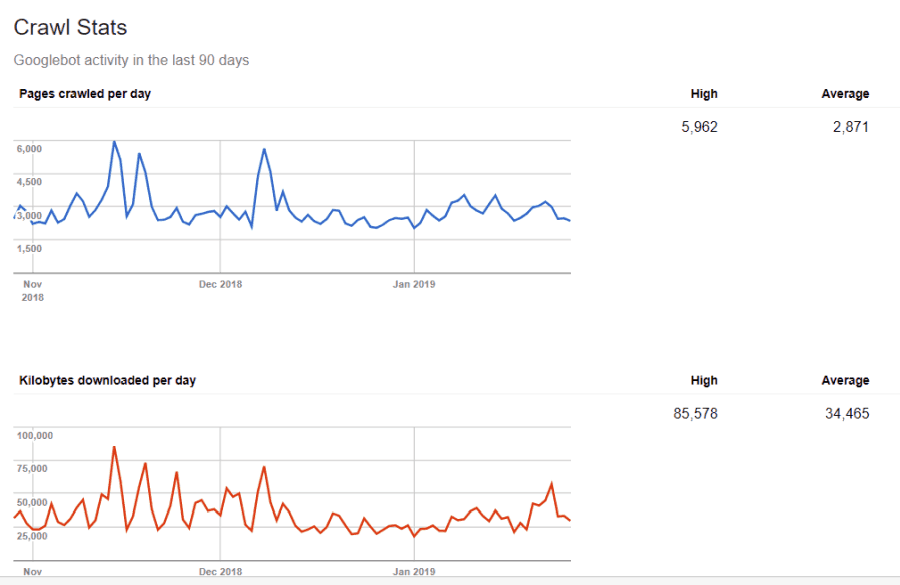
Comme vous pouvez le voir, le robot garde son activité sur votre site constante chaque jour. Il n’explore pas tous les sites, mais uniquement ceux qu’il considère comme les plus importants.
Pourquoi laisser Googlebot décider de ce qui est important sur votre site, quand vous pouvez utiliser votre fichier robots.txt pour lui dire quelles sont les pages les plus importantes? Cela empêchera Googlebot de perdre du temps sur les pages à faible valeur de votre site.
Les outils Google pour les webmasters vous permettent également de vérifier si Googlebot lit correctement votre fichier robots.txt et s'il y a des erreurs.
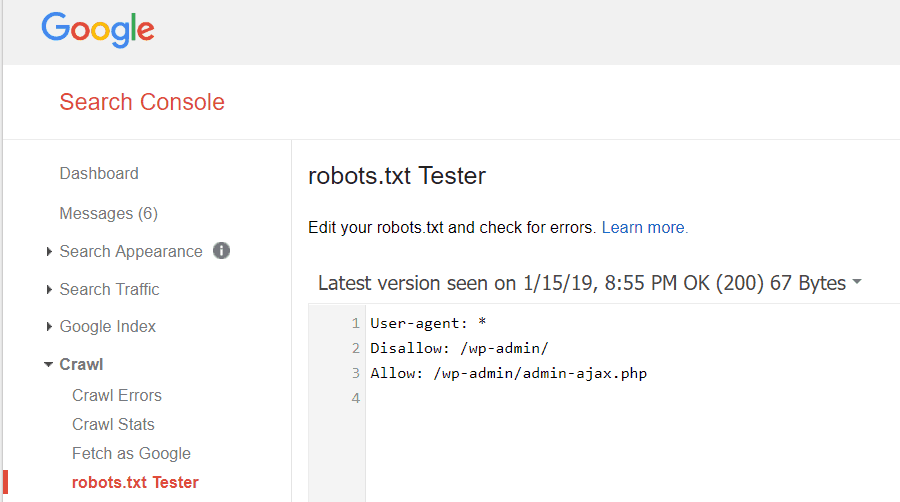
Cela vous permet de vérifier que vous avez correctement structuré votre fichier robots.txt.
Quelles pages devez-vous interdire à Googlebot? Il est bon que le référencement de votre site interdise les catégories de pages suivantes.
La plus grande erreur des nouveaux propriétaires de sites Web est de ne jamais regarder leur fichier robots.txt. La pire situation pourrait être que le fichier robots.txt empêche réellement votre site ou des zones de votre site d'être explorés.
Assurez-vous d'examiner votre fichier robots.txt et assurez-vous qu'il est optimisé. De cette façon, Google et d'autres moteurs de recherche importants «voient» toutes les choses fabuleuses que vous offrez au monde avec votre site Web.

